Alteryx Engine 和 AMP:主要区别
在 Alteryx AMP Engine 中,我们介绍 Alteryx Engine 以及新的 Alteryx Multi-threaded Processing (AMP)。在这里,我们将探讨这两者之间的主要区别。
数据处理差异
原始引擎架构主要支持单线程处理,数据会按顺序逐条记录进行处理,而新的 AMP 概念支持大规模多线程处理。为加快运行时速度,记录会以 4 MB 数据包的形式并行处理,这可能会影响输出记录的顺序。
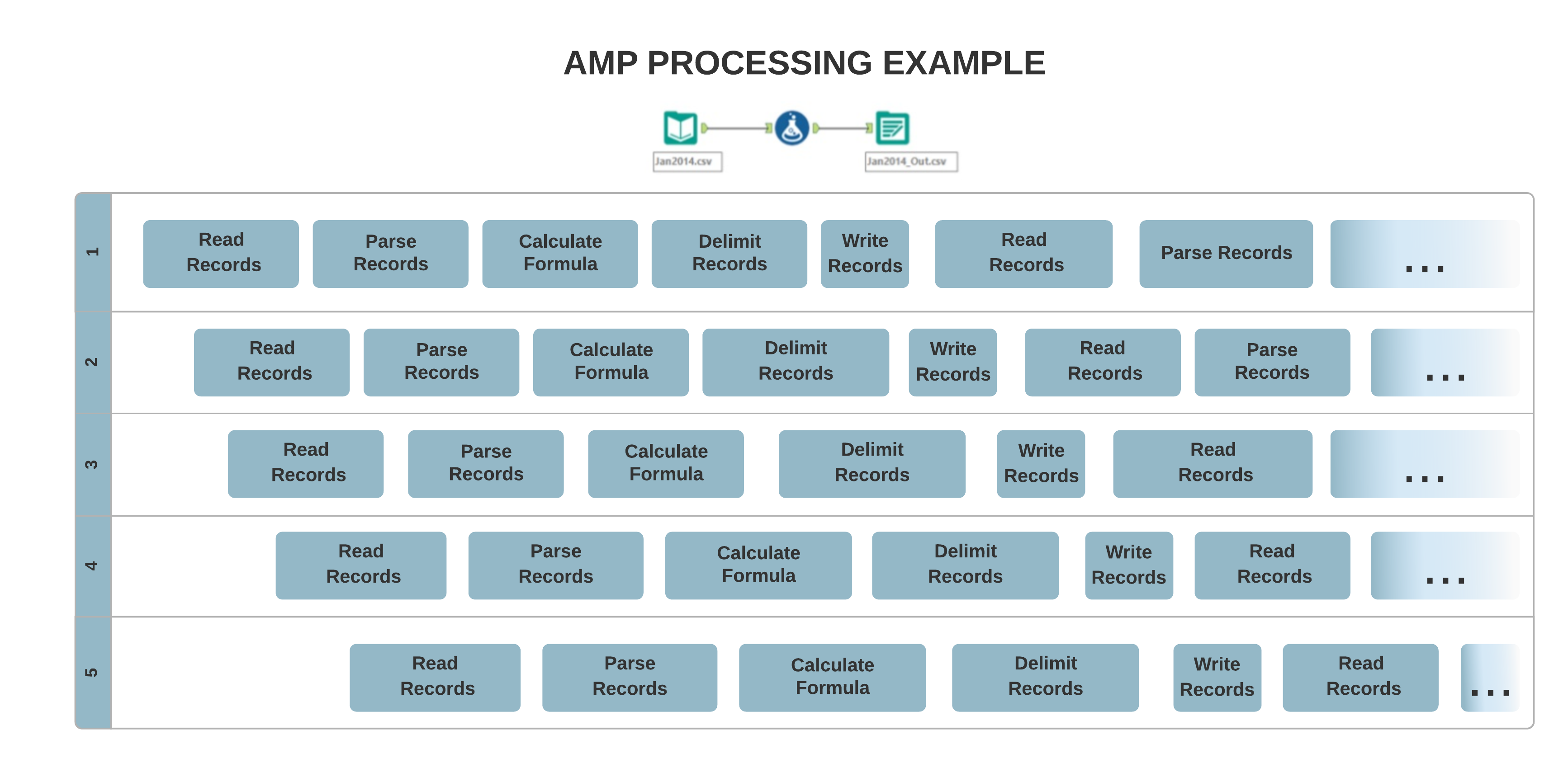
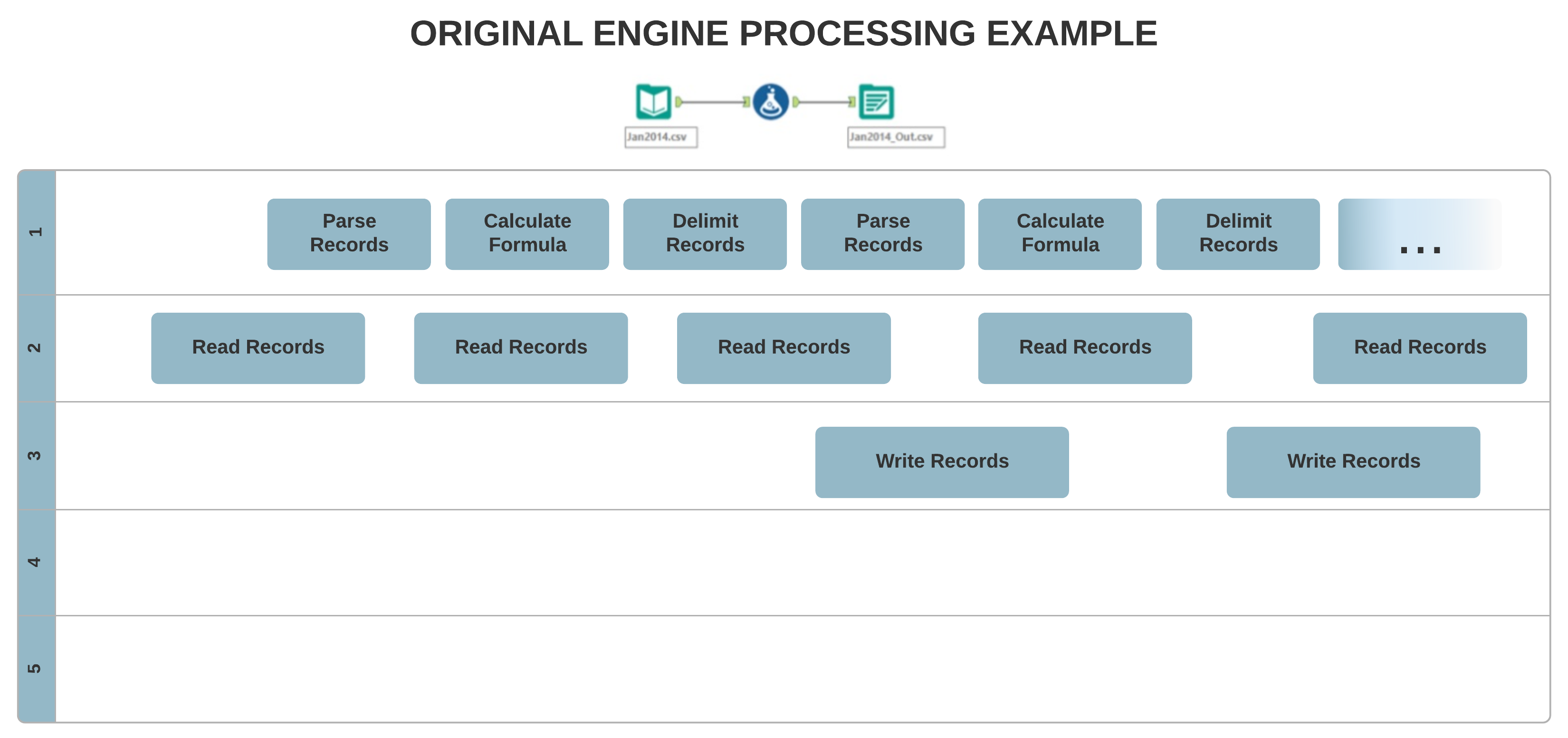
输入差异
记录限制
对于以下工具,在 AMP 上会启用工作流配置运行时设置所有输入的记录限制:
输入数据
文本输入
生成行
宏输入
在 2021.1 补丁 2 和所有后续版本中,增加了对动态输入工具中工具级别记录限制的 AMP 支持。
输出差异
在 AMP Engine 上运行工作流时,多个工具可能会以与原始引擎不同的顺序输出记录。其中一些工具包括……
交叉表
数据清理(移除null行)
连接
多项连接
多行公式
多边形构建
累计总计
排序(当字典排序与特殊字符一起使用时)
汇总(使用“分组依据”时)
区块
合并
唯一值
如果您的工作流要求上述工具中的记录按特定顺序排序以用于下游操作,则可以使用引擎兼容模式设置来保持与原始引擎相同的排序。在仔细考虑特定工作流后使用此选项,主要是将使用原始引擎创建的工作流改为使用 AMP Engine 运行时。
尚未转换为 AMP 的特定功能或配置将回退到该工具的原始引擎版本以实现正常运行。因此,同时包含 AMP 转换工具和非转换工具的工作流,可在 AMP 下无缝运行。
如果您对哪些工具已转换为 AMP 有疑问,请参阅在 AMP 上使用工具。
在原始引擎中,工具之间的耦合更紧密;一旦下游无数据,工具即停止工作。在 AMP 并行运行模式下,工具在下游为空时可能不会停止。此假设是指下游为空,而不考虑数据流。日志消息仅供参考。如果您非常在意数据流中的记录数,可使用测试工具:当获取的记录数不正确时,该工具会生成错误消息。
读取性能
使用 AMP Engine 写入的 YXDB 文件读取速度比使用原始引擎写入的 YXDB 要快。在启用 AMP 的情况下,使用原始引擎写入的 YXDB 文件的读取速度会变慢。但是,这些格式仍然兼容。
在 AMP 下使用 XLSX、CSV、YXDB 和 SQLite 文件格式 - 它们支持多线程读入数据。
读取 Zip 文件时,在原始引擎和 AMP 之间转换记录和打包会产出性能成本。这可能会导致使用 AMP 读取更大的 Zip 文件时速度明显降低。
提示
使用 AMP 写入的 YXDB 文件在文本编辑器中打开时,文件内容的开头会注明“Alteryx e2 数据库文件”。而使用原始引擎写入的文件在同一位置显示的是“Alteryx 数据库文件”。
写入性能
为了提高原始引擎的性能(让 AMP 写入由原始引擎创建的 YXDB 文件),请转到输出数据 - 配置菜单,在其中可选择创建一个与 Designer 版本 18.1 及以前版本兼容的 YXDB 文件版本。
在原始引擎和 AMP Engine 下保存 CSV 文件时,“输出”工具就包含 SpatialObj 数据的记录有着不同的处理方式。当保存为 CSV 文件时,AMP 会将 SpatialObj 数据写入文件,而原始引擎不会。这种差异会导致文件大小不同,可能会影响性能。
如果有必要,可以使用选择工具从记录中移除空间数据。这使得两个引擎能够以相似的持续时间完成。
性能分析
Designer 版本 2021.3 及更新版本支持使用 AMP 对各工具进行性能分析。
R 工具性能
AMP 以原始引擎格式与 R 交换数据。这种双重转换需要时间。在 AMP 上运行时,单个 R 工具的执行速度可能比使用原始引擎慢,但如果同时运行多个分支,则执行速度会更快。
文本输入工具和自动字段
AMP 解决了一个长期存在的问题,即字段大小不足而导致下游工具无法处理的问题。当生成的数据超过原始数据类型的长度时,无需添加“选择”工具来更改数据类型。AMP 为字符串和整数分配最大字段长度,确保后续操作有足够空间容纳更大的下游值。
When you use the Text Input tool, AMP provides more reliable and explicit data typing than the original Engine.
Original Engine: Automatically converts certain letter values like "F" and "T" into Boolean False and True. This can lead to unexpected type conversions when entering single-character strings.
AMP: Doesn't auto-convert "F" or "T" to Boolean. These values are preserved as String unless clearly defined as Boolean. This avoids unintended type changes and offers more predictable behavior.
节流工具
尽管节流工具尚未完全转换为 AMP,但仍可与下载工具配合使用(需先使用节流工具)。
模糊匹配
“模糊匹配”工具在原始引擎和 AMP 之间可能产生不同的结果。AMP 使用另一种方法匹配记录。匹配顺序可能不同,输出顺序也可能是相反的顺序。“模糊匹配”存在一个已知的性能问题,其使用 AMP 时的性能低于使用原始引擎时的性能。
正则表达式工具
AMP 使用 Unicode 和 Perl 编码标准,其中字符 $、+、<、=、>、^、| 和 ~ 不被视为标点符号。当使用公式函数 REGEX_Replace 或正则表达式工具通过正则表达式集 [[:punct:]] 来筛选标点符号时,使用 AMP 时,您需要更改表达式。
示例
REGEX_REPLACE([_CurrentField_],'[[:punct:]]|[\$\+<=>\^`\|~]','')
分组工具和阻止工具
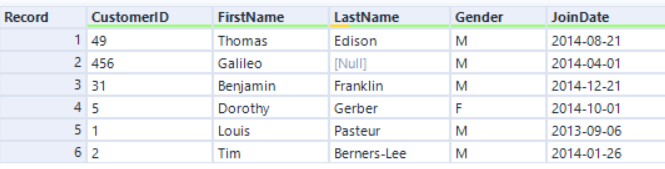
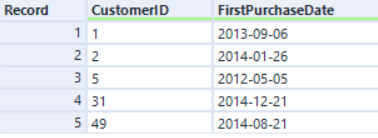
原始引擎的连接算法基于的是排序-合并连接方法,该方法下记录始终是以排序的顺序出现。AMP 的新连接算法基于哈希连接方法,因此输出的记录顺序是乱序的。例如......

左输入:
右输入:
在原始引擎下,若按客户 ID 进行连接,记录顺序将按客户 ID 字段排序:

使用 AMP 时,输出的记录相同但顺序不同:

如需对连接输出排序,请在连接工具后添加排序工具,或者在工作流配置 > 运行时的使用 AMP Engine 设置下启用引擎兼容模式设置。
迭代宏
当宏内的工具报告错误时,原始引擎和 AMP 之间可能会出现差异。使用单线程时,如果宏中发生错误,原始引擎将停止工作。AMP 会持续运行,直到迭代输出为空或达到最大迭代次数。您可能会因迭代次数增加遇到以下情况:
使用 AMP 时,错误数量(如有)可能会更多。
AMP 的记录数可能更高。
AMP 下的输出架构可能不同。
公式工具
公式工具中的 ConvertFromCodePage 和 ConvertToCodePage 函数接受字符串作为参数,并返回字符串作为结果,因此无法区分字符串是如何编码的。当这些函数与原始引擎和 AMP 一起使用时,公式工具的输出会有所不同。
AMP 在内部使用 UTF-8 编码字符串会导致输入数据的二进制表示形式不同。导入采用不同编码的数据时,将无法恢复原始数据。原始引擎将字符串存储为 Latin-1 或 UTF-16 编码的字符串,这些字符串用作缓冲区,且支持数据正确转换回原格式。
公式外接程序
AMP 尚不支持公式外接程序。如果需要运行包含公式外接程序功能的工作流,请使用原始引擎运行。
重要
从 2023.2 版本开始,公式外接程序通过 AMP 获得支持。
分析应用程序
使用地图工具从分析应用程序中的空间参考图层中进行选择的应用程序,应继续使用原始引擎。
预期相等
使用原始引擎时,预期相等仍然是 CReW 宏。在 AMP 中,它作为本机工具运行。
并行分支执行和工具运行顺序
某些工作流读取一个文件后写回该文件。这需要执行顺序控制,以确保读取在写入开始之前完成。同样,需在单个 XLSX 文件中写入多个工作表的工作流,必须一次写入一个工作表。Alteryx Designer 提供了一个“阻止直到完成”工具,帮助将工作分成互不干扰的阶段。
当您将先前分支的输出文件作为附件时,该解决方法同样适用于邮件工具。您需要等数据处理完成后,再将文件作为附件添加到电子邮件工具中。
当处理有多个分支的工作流(即从输入到输出基本上相互独立的多条流)时,将“阻止直到完成”工具放在输入工具 ID 编号最小的工作流分支中。这可确保每个后续分支在前一个分支完成后再运行,确保工具按预期运行。
可用功能
如需了解特定工具功能的更多信息,请参阅在 AMP 上使用工具。